Computation
Will the Next Unicorn be a Distributed Autonomous Organization?
With the recent talk of reddit being cannibalized by bitcoin technology, I thought it a good time to post something I’ve been thinking about for a while. Could a completely decentralized startup one day rival the likes of Google, Facebook and Amazon?
Within the bitcoin world there’s a common understanding that the most valuable thing about bitcoin is not the monetary currency but the underlying “blockchain” technology that the bitcoin currency runs on. For those unfamiliar, you can check out three heavily-funded ventures creating infrastructure that would enable anyone to program applications on the blockchain that go way beyond monetary currencies: Ethereum,Swarm and Blockstream.
One such application is what’s known as a “Distributed Autonomous Organization,” which is an organization like a corporation, government or NGO, but which has no central leadership and uses internet technologies to organize and function. Examples of DAOs that you are familiar with include open-source software systems like Linux; terrorist organizations like Al Qaeda; communities like Anonymous; and …
The Process
Imagine a multiverse, infinitely infinite. There’s just infinity. Or if you prefer, nothing. There’s no space, no time, no matter, no energy. There’s no structure whatsoever, and nothing “in” any of the universes that make up the multiverse. it’s not even clear whether these individual universes are separate from one another or the same. But since our minds seem finite and we have to start somewhere, let’s imagine them as separate: an infinite collection of universes with nothing in them, no dimension, and no relationship between them.
Now lets assume there is some process for picking out universes from the multiverse. Since there’s no time in the multiverse, the process has no beginning and no end. It’s like a computer program, but it’s infinitely complex. Let’s call it The Process.
If The Process is infinitely complex and has no beginning and no end, what can we know about it? We know that it picks some universes but not others, which effectively creates an “in …
Convergence
As readers of my blog posts know, I talk a lot about evolutionary systems, the formal structure of cooperation, the role of both in emergence of new levels of complexity, and I sometimes use cellular automata to make points about all these things and the reification of useful models (here’s a summary of how they all relate). I’ve also touched on this “thing” going on with the system of life on Earth that is related to technological singularity but really is the emergence or (or convergence) of an entirely new form of intelligence/life/collective consciousness/cultural agency, above the level of human existence.
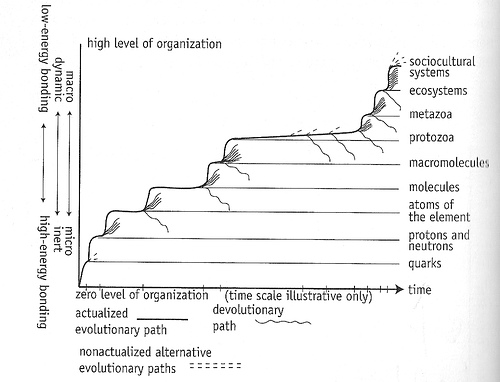
From The Chaos Point. Reproduced with permission from the author.
In a convergence of a different sort, many of these threads which all come together and interrelate in my own mind, came together in various conversations and talks within the last 15 hours. And while it’s impossible to explain this all in details, it’s really exciting to find other people who are on …
Foldit
Has anyone played Foldit, the protein-folding game that is designed to advance the science? This Wired article makes it sound like Ender’s Game meets biochemistry! Sounds like the Poehlman kid is the protein-folding equivalent of Stephen Wiltshire. I love the crowdsourcing, the meta-evolutionary algorithm of it (to find the savants), and the implications for science.…
Newcomb's Meta-Paradox
Tweeter, Claus Metzner (@cmetzner) alerted me to this cool area of study with this paper.
Suppose you meet a Wise being (W) who tells you it has put $1,000 in box A, and either $1 million or nothing in box B. This being tells you to either take the contents of box B only, or to take the contents of both A and B. Suppose further that the being had put the $1 million in box B only if a prediction algorithm designed by the being had said that you would take only B. If the algorithm had predicted you would take both boxes, then the being put nothing in box B. Presume that due to determinism, there exists a perfectly accurate prediction algorithm. Assuming W uses that algorithm, what choice should you make?…
Encoding Life's Complexity
Will Wright’s demo of Spore illustrates some key concepts of complex systems, including the notion of simple rules generating complex behaviors, and also the power of recursively applied (i.e. fractal) computation at different levels. Living systems leverage these same principles.…
Hive Mindstein
David Basanta’s blog has an interesting thread (quite a few of them actually). Here’s the setup but you should read the original post, including the Wired article:
…Apparently, some people are seeing some potential in cloud computing not just as an aid to science but as a completely new approach to do it. An article in Wired magazine argues precisely that. With the provocative title of The end of theory, the article concludes that, with plenty of data and clever algorithms (like those developed by Google), it is possible to obtain patterns that could be used to predict outcomes…and all that without the need of scientific models.
On the Brink of True Distributed Computing
[ The following is a repost from my MySpace blog, which is not accessible unless you have an account there. Also, the audience there isn’t really interested in this stuff :-) ]
The notion that the “network is the computer” - or at least that it could be - has been around for a while. But all actual implementations to date are either too specialized (e.g. SETI@home) or simplistic (e.g. p2p file-sharing, viruses, DDoS attacks) to be used for generalized computation, or are bound at some critical bottleneck of centralization. To this latter point, search engines hold promise, but the ones we are familiar with like Google are reliant on both central computational control (for web crawling and result retrieval) and central storage (for indexing and result caching). Lately social bookmarking/tagging has been used by those opting in to distribute the role of crawling, retrieval and indexing. It remains to be seen whether keyword tags and clusters thereof are semantically strong enough in practical terms …